TP3 - ML : classification ¶
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
Données¶
Présentation¶
Nous allons utiliser un jeu de données, au format csv, rassemblant des clients d'un opérateur de télécommunications.
Il possède 3333 lignes et 21 colonnes :
- Churn? : variable cible avec 2 modalités indiquant si le client a quitté son opérateur
- 15 variables "quantitatives"
- 5 variables qualitatives dont 2 "binaires"
Importation et affichage¶
Commençons par importer les données à l'aide de Pandas.
data = pd.read_csv("telecom.csv")
Affichons les données.
data
Affichons la structure des données.
data.info()
Données manquantes¶
Supprimons les variables (colonnes) avec "trop" de données manquantes
# data.drop(["...", "..."], axis=1, inplace=True)
Supprimons les individus (lignes) avec des données manquantes
# data.dropna(inplace=True)
Variables qualitatives¶
Affichons les statistiques des variables qualitatives (colonnes de type "object").
data.describe(include="object")
Attention, la variable Area Code est une variable qualitative qui se prend pour une variable quantitative.
data["Area Code"].value_counts()
Séparation¶
# variables prédictives
x = data.drop("Churn?", axis=1)
# variable cible
y = data["Churn?"]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y)
x_test
Le dernier paramètre stratify garantit que la variable cible possède la même distribution dans les deux échantillons.
y_train.value_counts(normalize=True)
y_test.value_counts(normalize=True)
Transformation¶
Echantillon d'apprentissage (données d'entraînement)¶
Variable cible¶
encoder = LabelEncoder()
y_train = encoder.fit_transform(y_train)
y_train
pd.DataFrame(y_train, columns=["Churn?"])
Variables prédictives¶
# variables qualitatives avec "trop" de modalités --> supprimer
var_aSupprimer = ["State", "Phone"]
# variables qualitatives "binaires" (2 modalités) --> transformer avec LabelEncoder
var_binaire = ["Int'l Plan", 'VMail Plan']
binaire_transformer = {}
for col in var_binaire :
binaire_transformer[col] = LabelEncoder()
x_train[col] = binaire_transformer[col].fit_transform(x_train[col])
# variables qualitatives ordinales --> transformer avec LabelEncoder
# variables quantitatives --> transformer avec StandardScaler
var_quantitative = ['VMail Message', 'Day Mins', 'Day Calls', 'Day Charge', 'Eve Mins', 'Eve Calls', 'Eve Charge',
'Night Mins', 'Night Calls', 'Night Charge', 'Intl Mins', 'Intl Calls', 'Intl Charge', 'CustServ Calls']
quantitative_transformer = StandardScaler()
# variables qualitatives nominales --> transformer avec OneHotEncoder
var_nominale = ['Area Code']
nominale_transformer = OneHotEncoder(handle_unknown='ignore')
# on regroupe toutes ces transformations dans un objet de la classe ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('aSupprimer', 'drop', var_aSupprimer),
('quantitative', quantitative_transformer, var_quantitative),
('binaire', 'passthrough', var_binaire),
('nominale', nominale_transformer, var_nominale)]
)
# on applique ces transformations sur les variables prédictives de l'échantillon d'apprentissage
x_train = preprocessor.fit_transform(x_train)
x_train
pd.DataFrame(x_train)
Retour sur la transformation de la variable Area Code
encoder_area = OneHotEncoder(sparse_output=False)
area = encoder_area.fit_transform(np.array(data["Area Code"]).reshape(-1, 1))
pd.DataFrame(area, columns = encoder_area.categories_)
Echantillon de validation (données de test)¶
# on applique la transformation à la variable cible de l'échantillon de validation
y_test = encoder.fit_transform(y_test)
# on applique les transformations sur les variables prédictives de l'échantillon de validation
# attention aux variables "binaires" qui ne sont pas transformées dans le preprocessor
for col in var_binaire :
x_test[col] = binaire_transformer[col].fit_transform(x_test[col])
x_test = preprocessor.fit_transform(x_test)
pd.DataFrame(y_test)
pd.DataFrame(x_test)
Apprentissage¶
Choix du modèle¶
On importe la classe du modèle choisi.
from sklearn.neighbors import KNeighborsClassifier
Création du modèle et choix des éventuels hyper-paramètres (validation croisée)¶
Pour le modèle choisi, on crée un objet à partir de sa classe en fournissant les éventuels hyper-paramètres.
# pour commencer, prenons les hyperparamètres par défaut
modele_knn = KNeighborsClassifier()
Apprentissage du modèle¶
On ajuste le modèle créé à partir des données d'entraînement.
modele_knn.fit(x_train, y_train)
Validation du modèle¶
Avec le modèle ajusté, on peut prédire la valeur de la variable cible pour les individus de l'échantillon de validation.
y_predict_knn = modele_knn.predict(x_test)
On peut enfin valider notre modèle en mesurant sa qualité à l'aide de certains indicateurs : précision, sensibilité (recall), F1-score, ...
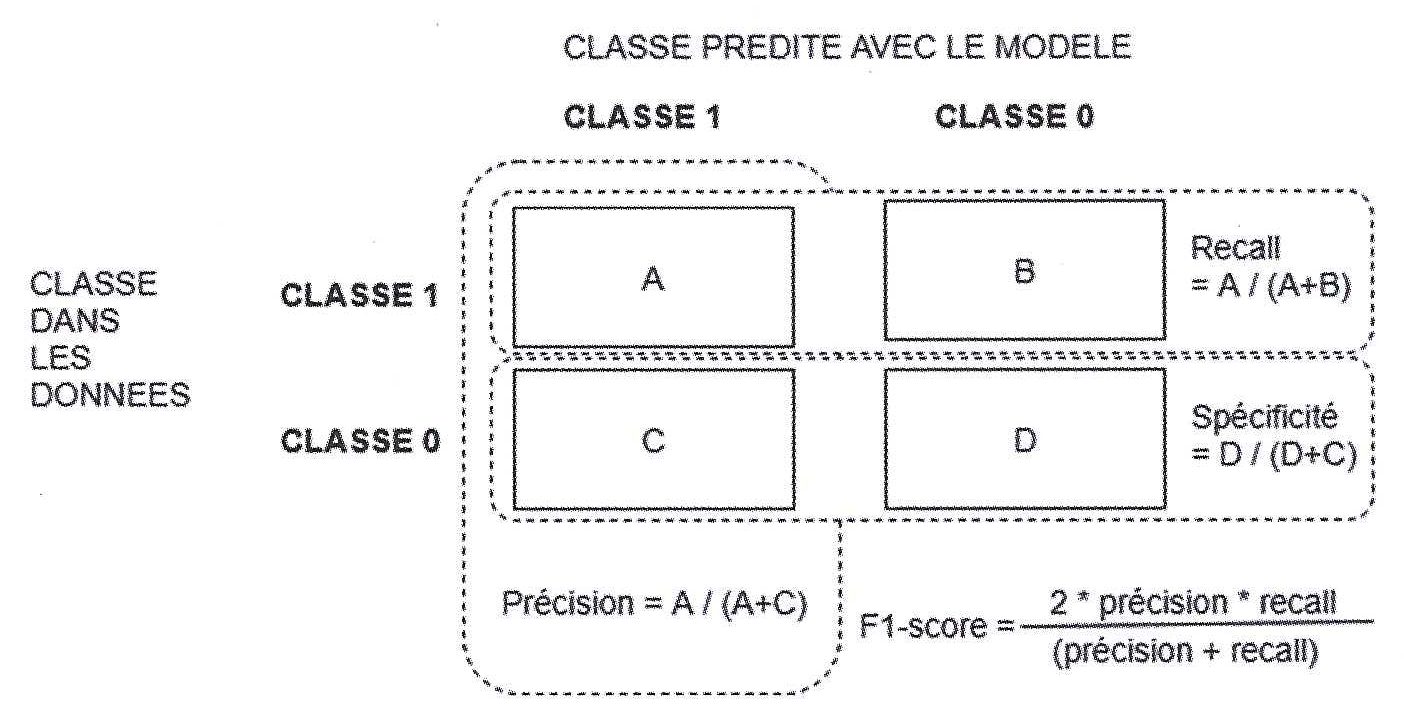
from sklearn.metrics import classification_report
print("Rapport pour le modèle kNN :", classification_report(y_test,y_predict_knn), sep="\n")
A l'aide des probabilités d'appartenance estimées par notre modèle, on peut tracer la courbe ROC qui représente la proportion de vrais positifs en fonction de la proportion de faux positifs.
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
# on extrait les probabilités d'appartenance
proba_knn = modele_knn.predict_proba(x_test)[:,1]
# modèle kNN
fpr, tpr, _ = roc_curve(y_test, proba_knn)
plt.plot(fpr,tpr,":", label="kNN")
# modèle aléatoire
plt.plot([0, 1], [0, 1],"r-", label="aléatoire", )
# modèle parfait
plt.plot([0,0, 1], [0,1, 1], 'b--', label="parfait")
plt.xlim([-0.01, 1.0])
plt.ylim([0.0, 1.05])
plt.legend()
plt.show()
L'aire sous la courbe ROC (AUC) est un bon indicateur pour comparer plusieurs modèles et sélectionner le meilleur (aire la plus proche de 1).
from sklearn.metrics import roc_auc_score
auc_modele_knn = roc_auc_score(y_test,modele_knn.predict_proba(x_test)[:,1])
print("Aire sous la courbe ROC pour le modèle kNN :" , auc_modele_knn)
Sélection du meilleur modèle¶
Retour sur le choix des hyper-paramètres (validation croisée)¶
Nous allons faire varier les hyper-paramètres de notre modèle pour trouver la meilleure combinaison au regard de l'AUC.
from sklearn.model_selection import GridSearchCV
# construction du dictionnaire d’hyper-paramètres
dico_param_knn = {"n_neighbors":[2,5,10,50], "weights":['uniform','distance']}
# création du "modèle de comparaison"
modele_grid_knn = GridSearchCV(modele_knn, dico_param_knn, scoring="roc_auc", cv=5)
# ajustement des différents modèles et sélection du meilleur
modele_grid_knn.fit(x_train, y_train)
# affichage des meilleurs paramètres et de l'AUC associée
print("Meilleurs paramètres kNN:", modele_grid_knn.best_params_)
print("AUC - kNN:", modele_grid_knn.best_score_)
Autres modèles¶
En vous inspirant de ce qui précède, ajustez et calculez l'AUC pour les modèles suivants :
- Régression logistique (hyper-paramètres par défaut)
- SVC (hyper-paramètres par défaut)
- Forêts aléatoires (meilleure combinaison pour le dictionnaire d'hyper-paramètres {"n_estimators":[10,100,1000],"max_depth":[5,7,9]})
# Régression logistique
from sklearn.linear_model import LogisticRegression
# SVC
from sklearn.svm import SVC
# Forêts aléatoires
from sklearn.neighbors import KNeighborsClassifier
Conclusion¶
Quel est le meilleur modèle ?